a product of:
![]()
To contact:
Feedback is welcome! If you find this useful, let us know. If you agree/disagree, let us know.
If you find this resource valuable, considering sponsoring this work.
Overview
As we consider the efforts of humans, we see success and failure. We observe projects that go well, and those that do not. Why is this? A complete answer is beyond the scope of this document, and beyond the ability of any one person or group of people to fully understand. There are many aspects of human life including the physical, social, environmental, emotional, psychological, and spiritual -- all powerfully affect and influence people. With our finite time and understanding, we are going to focus on two aspects of human endeavor and how they relate to success:
- scale
- flow
Scale is the ability to move an endeavor (project) beyond one person. A single person can accomplish very little in this world. Unlike many of the animals, we are helpless on our own. The progress that allows us to live in a comfortable home, drive an automobile, and type on a computer are all the result of countless human efforts -- each building on previous efforts. Even the most notable of humans is a but a tiny blip in the chain of human progress. Yet most people live in a delusional bubble that the world revolves around them. If what we do cannot be used by others, we will likely have contributed very little to the overall human condition beyond subsistence and our own personal wealth which is like a vapor that appears for a moment, and then is gone. The effort and discipline required to scale any effort beyond one person to even a few people is immense. It requires a completely different mindset.
Flow, in the context of human endeavor, is when things proceed along smoothly with continuous contributions and improvements -- like a smoothly running flywheel that is started with great effort, and then gains momentum with each incremental push and never stops. This can be contrasted with endeavors that resembles dragging a large object up a hill. We jerk it along alone with starts and stops until we are exhausted. We leave the object and beg and cajole others to help us. With a group we make rapid progress for awhile, but then all are exhausted and stop. Some leave. There is bickering and politics that some are not pulling their load. We argue if pushing or pulling is better. If we are not careful to brace the object, it may roll back down the hill at times. Which analogy do your projects most resemble and why? The reality is likely somewhere in the middle, but these extremes help us think about the big picture.
The TMPDIR handbook is a collection of observations and best practices. These practices are designed to scale efforts beyond one person and achieve a reasonable state of project flow. Although some practices may be specific to areas the authors have worked in (hardware/software development), much should be generally applicable.
Some specific goals might include:
- encourage and enable collaboration
- minimize mistakes
- reduce bureaucracy
- add process where beneficial
- connect you with the right people
- foster innovation
Process
Process is a tricky thing to get right. Implemented poorly, it adds bureaucracy, friction, and bottlenecks. Process implemented with a reactive mindset limits what people can do and seeks to minimize damage due to a lack lack of integrity and trust.
Process implemented properly decreases friction, automates tedious tasks, and increases transparency. Because there is transparency, there is accountability and trust. Process implemented with a progressive, forward looking mindset enables people to do more. If something needs done, anyone on the team is free to do it. But, because there is a process that records everything that is done, there is also transparency and accountability.
The Collaborative Mindset
The collaborative mindset works with the intention of enabling others and communicating in an open and transparent fashion. Tools like Git allow all communication (commits, tickets, pull requests) to happen in the open, but people are free to ignore happenings that are not relevant to them. Instead of design discussions happening in emails or meetings, a developer with an idea might modify some documentation, create a pull request (PR) and tag others to ask for review on the ideas. Discussion will follow in the pull request comments. Another person who was not tagged in the PR might notice the PR in log in the Git portal home page, decide it looks interesting, and offer a comment. Other PRs can be easily referenced. We typically think of PRs happening in the context of source code changes, but why can't they be just as effective for documentation and design? However this is a big mindset change to shift away from emails and meetings that we are accustomed to using.
Scarcity vs Abundance Mindset
There are two approaches in business -- one is to view opportunities as a fixed pie and try to get the largest slice possible. The other approach is to grow the pie so there is more opportunity for everyone and the slice you have gets larger as well.
Gatekeeper vs Enabler Mindset
Related to the scarcity vs abundance mindset is the distinction between our role in projects and companies. Are we a gatekeeper, or an enabler? A gatekeeper tightly controls who can do his job, thus tends to do things in a closed way. Enablers do things in an open way that enables others to easily contribute. The enabler mindset is not a free-for-all as there can still be reviews, checks, and quality standards. But, there are no barriers to work shifting to whoever has time and interest.
Effective
Personally and organizationally, we desire to be effective and useful. Many of the principles we find effective personally, are also effective organizationally, but are often more difficult to apply organizationally.
Attributes of Successful People and Organizations
- Humility. This has been well researched by Jim Collins in his book Good to Great. There are few people who are humble, and even fewer organizations.
- Truth, the foundation of all success. Honesty is a component of this -- do we see things for what they are?
- Improvement. We are either moving forward or backward, there is no standing still. Those who "have arrived" are in decline. Are we continually learning? Do we leave things better than when we found them?
- Collaboration. On their own, humans can do very little. We are highly dependent on others. Smart people don't always know everything but often don't realize it. Effective people (and organizations) acknowledge what they don't know and connect with those who do.
- Excellence. My grandfather had a sign above his desk that said "Good enough is not good enough." Do we do the best possible job we can with the resources and time we have?
- Generous. What we give comes back to us many times over. Are we fair in our dealings?
- Discipline. Will and strength to focus on what needs done, and ignore other distractions.
- Vision. We have some idea where we are going. Is there meaning and purpose?
- Trust. The foundation of successful human collaboration. Nothing can replace this.
- Care. Do we care enough to understand others? Do we listen? Do we encourage others? Many succeed personally, but it is much harder organizationally.
We notice a trend here -- positive attributes are more difficult to find in organizations than individuals. Organizations can be structured to leverage the strengths of its individual members, or it can be reduced to the lowest common denominator of its members. What is the difference?
Attributes of Successful Teams and Projects
Below are some of the attributes of teams/project culture that contribute to success:
- intrinsically motivated people (you have to start with this)
- very clear goals (with milestones)
- clear list what needed done and who is assigned to what specific task
- good communication
- communication is centered around documentation
- even though it is distracting at times, the best projects used instant/group messaging (skype, hangouts, signal, slack, etc) quite a bit. This seems important for relationships.
- good use of issue tracking system (Trac, Github/Gitlab/Gitea issues, Trello, etc)
- occasional face to face meeting (perhaps once or twice per year).
- developers get feedback on how what they are building is used.
- no politics.
- freedom to express thoughts and respectfully disagree with others without fear of repercussions
- no turf or rigid roles -- people did what needed done, and did not worry about stepping on someone else's toes
- openness - state of the project, how company was doing, field successes/failures was clearly communicated to all on the team
- everyone on the team had access to the same project resources, source code, etc.
- no barriers to communication -- you communicate with anyone on the project (even customers at times) and did not have to funnel information through a PM. However, because of the workflow (issue tracking system), a lot of communication (especially status and decisions) was also accessible to anyone on the team as needed.
- no blame culture. Mistakes will be made. Focus is on improving process, testing, etc. instead of blaming people when things go wrong. (Note, this does not excuse lazy or unmotivated people -- that is a different problem than making mistakes)
- low friction work-flow where experienced people review/approve work of less experienced people, but anyone is free to do anything needed.
- bias toward action, building, and early testing.
Optimize where it will make a difference
A comment we sometimes hear when we ponder approaches is "Just keep it simple!" The question we then must ask is "from whose perspective?" With any optimization or trade-off, we need to always ask this question.
A few perspectives to consider:
- R&D
- time to market
- maintenance
- support
- end user
- sales
- manufacturing
- quality
- management
- financial
- business owner
- IT
- legal/IP
- security
It can be a little overwhelming when you consider how long the above list can be. One approach is to consider who is spending the most time with the product. Hopefully this is the user, otherwise the product is not successful. If you don't optimize for the user's experience, then someone else will. The next categories might be manufacturing/maintenance/support/sales -- at least for a long lived product. Sustaining development effort far outweighs initial development on most products. Additionally, sales, manufacturing, and support efforts continue as long as the product exists. The time developers spend working on a product swamp that of management and support functions like IT. We obviously need to balance the concerns of everyone involved, but if we optimize the tooling and flow for those who are spending the most time with the product, that will probably pay the largest dividends.
Another approach to consider is try to implement tooling and processes that benefit multiple perspectives. Some ideas to consider:
- select tooling that is open and can be customized as needed. Too often proprietary tooling is selecting from one perspective and it can't be easily adapted as new needs arise.
- ensure access to information is open. For example, if management has clear visibility and access to development workflow, then less meetings and manual reports will be required. If development has easy access to support and user information, they will do better job building something. The more easily information is shared and organized across organizational boundaries, the better things will go.
- automate - automate - automate. If something needs done more than a few times, automate it. This requires prudent technology selections that are amenable to automation and customization.
- remove unnecessary roadblocks and gatekeepers. If something needs done, make sure anyone with the skills can do it. Mistakes are costly, but not getting things done is likely more prevalent and more costly. The difference is the first is highly visible, and the latter can be hidden quite easily.
- focus on effective measurements that are visible to all. It's hard to improve without measurements.
The Development Process
Contents
The development process has been extensively researched and there are many processes or methodologies that have been proposed over time. This document attempts to identify simple concepts that will be generally useful.
Documentation
Documentation is an important part of the development process. See the Documentation chapter for more information on this topic.
The Development Triangle
Life is full of trade-offs – product/software development is no different. Fast, Cheap, Features … pick two. Want all three? Then quality will suffer.
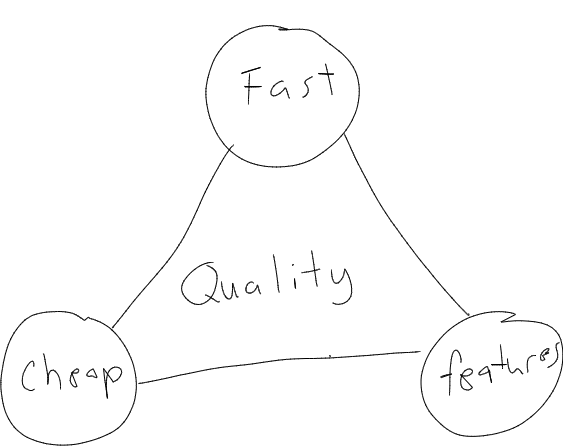
Why is Iteration important?
There are several attributes of modern systems that are perhaps different than systems in the past:
- They are often complex such that no one person understands the entire system, or can even visualize all the possibilities. The most innovative and useful systems are a combination of many good ideas.
- There are plenty of resources for expansion (memory is cheap, processors are powerful, standard interfaces like USB allow for easy expansion)
- The system can be upgraded (software updates are standard)
- The problems they solve are complex and the problem often changes once people try something and better understand what can be done.
- Perfection comes from refining ideas, trying things, etc.
The software industry has long understood this and most development processes have moved from a waterfall to agile type methods. However general project and hardware development thinking tends to lag -- partly due to practical considerations such as the cost of building physical prototypes. However, these costs are becoming lower and lower each day and innovative companies have embraced iteration. As this article states so well:
Apple does this with their hardware. Why don’t you?
Business Relationship Models
The simple way of managing projects is the "throw it over the wall model." In this model, you typically have a gatekeeper that manages the over-the-wall transition.
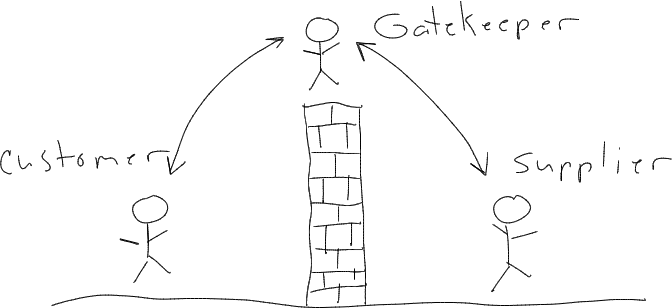
This model works fairly well for simple systems or components that can be clearly specified and no iterations are required. In this case, an experienced gatekeeper may be able to add a lot of value in managing the process. Gatekeepers may be a consultant, distributor, manager, purchasing agent, etc. However, as the complexity of a system increases, the gatekeeper increasingly finds they don't know everything about the system. Instead of improving the process, they become a bottleneck.
As systems become more complex, the need to collaboration and project iteration grows -- the success of open source software has long proven this. Thus having processes where all parties involved can easily collaborate is critical.
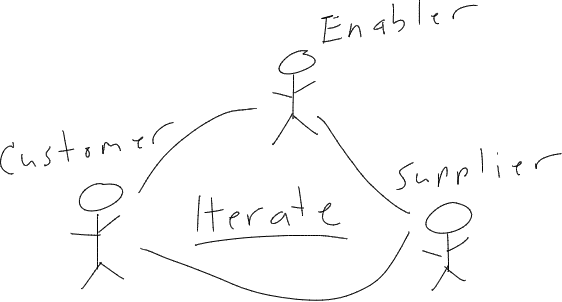
If open processes are not in place, the following happens:
- the best ideas are never discovered, as the right people never work together
- problems are extremely difficult to solve as the right people don't have visibility
- motivation suffers because not everyone gets to share in the project success or failure
- things move extremely slow
Thus, for modern systems, it is important to foster processes and environments that encourage openness, collaboration, and iteration.
Collaboration
Contents
- Why is collaboration and process important?
- Openness and Transparency
- The long term vs short term mindset
- The Role of Email
- Instant Messaging
- Meetings
- Kanban Boards
- Deep Work
Why is collaboration and process important?
Why is collaboration in a company, project, or organization important? There are many reasons:
- As systems increase in complexity, no one person knows everything about all the technology in a product, or has time to implement it all. Collaboration with experts is the only way to build complex systems.
- Just as in product development where no one person has all the knowledge needed, how much more in the complex operations of a company composed of humans. A company's success depends on its ability to leverage good ideas of all involved, and there needs to be a process for these ideas to surface.
- If design specifications are collaborative, vs authoritative, then they become a way for a team to think about the design. As Leslie Lamport advocates, thinking above the code is important.
- Although it is important to think about a design up front, complex systems cannot be completely specified up front. They evolve based on what we learn during implementation, feedback from users, and changing requirements. Development is an iterative process. If specifications and documentation are not an integral part of the working development process, they quickly become out of date an irrelevant. If specifications are maintained by one person on the team, they are likewise destined to become outdated and irrelevant. Everyone on the team needs a low friction way to edit and update documentation. The best case is if documentation becomes a useful tool during development -- a way to think, communicate, and collaborate.
- A company is a collection of people. If people have a voice, they will be much more motivated than those who are simply told what to do. The command and control model of yesteryear does not work today.
Openness and Transparency
People and organizations vary widely in the degree to which they are transparent and open. Transparency and Openness are not exactly the same thing -- transparency is the degree to which we can see things. Openness is the quality of being open to ideas and feedback. Both are necessary in a successful team. Transparency is more about the process, and openness is more about the culture -- both work together.
Share your work early and often. With Git hosting platforms like Github, this is very easy to do. You simply push your working branch to a remote repo at regular intervals -- at least daily while doing active work. This has many benefits:
- Others can optionally look at what you are doing and can provide feedback. Note, optionally is the key word -- they don't have to look or respond like they might feel compelled to if you directly email them.
- Early feedback is valuable as others may have feedback that impacts the direction your implementation takes -- especially related to the business needs of the work.
- Sharing your work injects energy into the team. It is motivating to others to see things getting done. It is like the difference between a fast flowing mountain stream and a stagnant pond -- which is more inspiring?
- Small changes with good commit messages tells a nice story about a piece of work and is easy to review. Others can follow and understand what is doing without you having to explain as much. These stories are valuable later if anyone (usually ourselves) needs to go back and review why we did something the way we did.
- Monster commits/PRs are exhausting to review and end up not being reviewed.
- Commit messages are a form of writing and writing helps us think better.
- We do better work in public. Part of this may be accountability but part is simply how we work -- it is motivating.
Possible objections and counter responses:
- My code is not perfect.
- (Most people care more about things getting done than perfection. We all make mistakes and write sloppy code to prototype or experiment with things. That is perfectly acceptable.)
- I don't want to bother people.
- (Git commit messages are easy to ignore. However, if the commit comments are good, someone who is casually observing the stream of work going by may see something that interests them and then take a closer look.)
- It is only an experiment and may get redone anyway.
- (It is perfectly fine to do a git force push and rebase your changes. This is why these Git features exist. The Git hosting platform will still record the history in the pull request, which is instructive in showing others how you reached your solution, and it helps you as well better understand what you did.)
- I'm not comfortable showing my work.
- (There may be many reasons for this. Some people are simply more private. Some feel insecure. Others have had bad experiences in the past where their work was criticized. As developers, we need to have thick skin -- not in the sense that we don't care, but that we are need easily offended. Many who share feedback are not trying to be harsh or critical, but simply have opinions on how things should be done -- we need to get used to this. As with anything, the easiest way to improve is to practice. If we share early and often, we'll learn how to deal with feedback.)
- I don't have time for this.
- (If you are working on short term solo project, then this may be a valid argument. Otherwise, see long term vs short term mindset.)
Teams should have a cultural expectation that if you are doing work, there should be commit messages, issue comments, something flowing in the stream of changes. This may be documentation, notes, test code, todo lists, test results, whatever -- just something. Even if we are only sketching in our Moleskine notebook, we can still snap a photograph and share that.
The long term vs short term mindset
Team work and collaboration is all about doing things in a slightly less convenient way personally to make our work more transparent and helpful for the team long term. Discussions in a Kanban board or Git pull request are less convenient then sending a quick email. Creating a Markdown document in Git is less convenient than firing up Word and emailing an attachment. Creating granular Kanban cards for every task you do on a project is less convenient that just diving in and doing the work. Using open source tools that are available to anyone on the team may be less convenient than using a commercial tool we are used to, but others do not have access to. Storing files in Git is less convenient that a file server. Doing working on Git branches and opening pull requests is less convenient than just pushing to master. Short term, this all seems like overhead and more work. However, long term there are huge dividends. Discussion happen in the context of work being done and are easy to find later. The drudgery of status reports are eliminated because workflow is transparent and meetings transition to creative discussions, brainstorming, and solving hard problems. Conversations are centered around documentation rather than documentation being created as an afterthought and often forgotten. Individuals are no longer a bottleneck to work getting done. Changes are grouped in logical pull requests that are easy to review when merged and referenced in the future. Reviews allow us all to learn. Everyone has the access to tools to review and fix anything any time any where. Long term maintenance is greatly simplified. We understand what we are building. We see who is doing what. We understand why things are done they way they are. The history of what we have done can be leveraged for future decisions. We can visualize the flow of work. Above all, we have clarity into what we are doing and why. Working with clarity brings many intangible benefits that are not easily measured. Optimizing for the long term always requires some personal sacrifice short term, but good tools and methodologies minimize this personal sacrifice and often accrue personal benefits many times over any investment we may have made. As an example, once people learn Git (and there is a learning curve), they use it for all projects -- even when a team is not involved as it is a better way to work. Good workflow and tools takes the drudgery out of many repetitive tasks, reduce errors, increase transparency, and free us to do creative work that adds value.
The Role of Email
Email is an amazing communication tool. It is one of the marvels of the Internet age and along with HTTP, perhaps one of the few truly distributed information tools available that no one company controls. The distributed nature of email (compared to silos like Linked-in, Twitter, Slack, etc) is vastly undervalued in this age of large companies centralizing and monopolizing communication. However, the negative aspect of email is that anyone can send you email and most legitimate users tend to use it too much. Thus many people don't get much done other than process email. We also tend to put too much information in emails. Email is a very poor knowledge repository for the following reasons:
- it is not an accessible shared resource, especially for new people. Have you ever tried to search someone else's inbox?
- it is difficult to organize. You can have folders and tags, but you can't easily link from one email to another, which is a fundamental requirement of a good information system and the superpower of the Web.
- content cannot be updated or improved over time -- it can only be replied to.
email is where knowledge goes to die
There is a better way, and that is to communicate about work with documentation and issues in a tool like Github, Gitlab, or Gitea. If you want to propose a new feature, or change how something is done, create a branch, modify some documentation, and then open a pull request to discuss with others. This way any outstanding discussions are captured in open pull requests rather than being lost in the black hole of someone's inbox. Do we want to know what is outstanding -- simple, look at outstanding issues and pull requests.
Old style maillists perhaps work around some of these issues with public list archives, and have been successful in various OSS projects, but these style lists are almost never used/accepted in company/business settings and are most suitable for highly technical people working on very large OSS projects like the Linux kernel. Smaller teams are better suited by a modern Git based workflow.
Email is very useful for discussions or to receive notifications from tools like Github or Gitea (these emails can be deleted with no thought as we know the information is captured elsewhere) and for communication that does not fit anywhere else (ex: communication with people outside your organization). But if there is a bit of information in an email that you want to save or make available to others long term, it should be transferred somewhere else -- to a shared documentation/collaboration system, or your own Notes system.
Some companies go as far as deleting all email older than 3 months old. This is probably done to limit liability, but it is an excellent policy to help push people in the right direction -- don't depend on email to store long lived information.
Reference:
- Email is Where Knowledge Goes to Die (Bill French)
- Email is where knowledge goes to die (Rolf Lindström)
Instant Messaging
Instant messaging tools (like Signal, Google Hangouts, Slack, etc) can be useful in collaboration in that they enable team members to strengthen relationships. Signal is a good choice because it is simple to use, is end-to-end encrypted (so they respect privacy), and there are both mobile and desktop clients. Slack may be better for larger teams. Git notifications can be fed into a slack channel to provide the team with a view into the work stream. Discourse not has chat functionality making it a very powerful collaboration platform for teams. Chat messages can be easily be turned into Forum topics to make them more accessible long term.
Meetings
Meetings are an interesting dynamic and perhaps one of the hardest things to get right. At their worst, meetings are boring and a waste of time. At their best, they can be invigorating and very enjoyable. The COVID experience has really caused us to appreciate the value of the face to face experience. However, many meetings (could be a formal business meeting or spending time with friends/family) we still don’t really maximize the value of being in-person with someone. In a meeting, everyone should be engaged during the entire meeting. This means things need to keep moving. The focus needs to be on interpersonal interaction, solving hard problems, brainstorming, making decisions, etc – things that engage people. If one person does most of the taking, it is not a meeting, it is a presentation.
The trend in meetings today is that most are looking at their computer or phones most of the time vs being fully engaged with each other. This could mean several things:
- we are doing work during the meeting
- people are bored and are not engaged
- we have not prepared for the meeting
Perhaps this is a natural result of spending a lot of time on virtual meetings, where we soon get used to working through meetings because we can get away with it. However, this is a suboptimal use of time because we are trying to do two things at once and it is likely we are not doing either one very well. If we are not fully engaged in a meeting, do we really need to be there?
If we can remove the mundane from the meetings, then this opens up opportunity for more engaging/creative discussions. Gitlab’s approach is rather profound:
We actually place a very high burden on meetings, and we do it intentionally, so that meetings are not the default. And if you create a culture where meetings are hard to have and it’s not the default, then sure enough, the next path of least resistance will become the thing that people go to, which in our case is documentation.
...
And then after the meeting you have to look at the takeaways in the Google Doc, which is just a temporal home, and you have to say “Alright, if anything in this meeting matters to more than just me, I have to go find the right place(s) in the handbook and make a merge request to actually add this to the handbook”, because the handbook is the ultimate single source of truth, where all of the company would go to to find the latest and greatest information on whatever the topic is. So what I’m saying is that’s a lot of work in a meeting…
Documentation should be the center of real work. If decisions and thinking are not captured for easy access by others, it is of limited use and will likely soon be lost. It is also important that thoughts be captured in a format that can be easily modified and expanded on in the future. This is the power of content stored in Git with pull requests – the thinking does not stop at the end of the meeting, but rather the meeting can be the start of something that continues on in one continuous flow of creative thought as people collaborate, open pull requests, discuss them with comments, meet again to brainstorm and solve hard problems, etc. A meeting is then not a disruptive speed bump in your schedule, but rather a well synchronized input into the flow of creative work, which all revolves around fluid documentation and never stops. Meetings are not for status reports, boring monologues, power posturing, etc, but rather to maximize the creative output of a group of people working together in real time.
For more ideas on the topic of meetings, see:
[Brain Drain: The Mere Presence of One’s Own Smartphone Reduces Available Cognitive Capacity](https://www.journals.uchicago.edu/doi/epdf/10.1086/691462)- Gitlab's approach to meetings
- Seth Godin's ideas
- Naval's appoach
Kanban Boards
are useful tools for managing work and creating flexible and ad-hoc work-flows. These boards can be implemented using post-it notes on a wall, or with digital tools such as Trello. Typically a Kanboard board will have backlog, doing, and done lists to clearly the status of work. Items may be sorted in the backlog according to priority.
Some points that make Kanban boards work well:
- You can at a glance see what is going on.
- All discussion happens in the card, so it is easy to find and refer to later.
- Discussions have context (documents, photos, links, previous comments, etc). Everything is together rather than being in disconnected email threads, instant messaging comments, file server files, etc.
- Workflow and processes can be managed by dragging cards from one list to another. Example sales -> orders -> part procurement -> production -> shipping -> done. These lists could be split into separate boards as needed.
Suggestions for making Kanban boards work well (the following applies to Trello, but other tools may be similar):
- Try to keep the number of lists to a number that they fit horizontally on a computer screen. If you need more lists than this, then create more boards. It is easy to move cards from one board to another.
- If you have too many lists to fit on a screen, keep the most important ones, such as doing, to the left, so they show up when you load the page.
- Use screenshots extensively. A picture is often worth a thousand words -- paste screenshots into cards to convey status, results, problems, etc. This makes cards more interesting to read. It is often quicker to screenshot some code in an editor than try to do a text copy and get the result to look right.
- Create a trello board that is your "library". This can contain lists of reference information, documentation, cards with datasheets, etc. The ability to add comments allows you to add meta information and makes the library more useful than just dumping a bunch of PDFs on a file server.
Deep Work
Collaboration is essential, but you should consider allocating blocks of your day where notifications are silenced so that you can focus on deep work. Even if you only allocate 3 hours a day to deep work, it amazing what you can get done in this focused time if it is uninterrupted.
Git
Contents
- Metadata
- Parts of a Git System
- The Pull Request Flow
- Workspace and remote repos
- Branches
- Working with branches
- Getting change notifications
- Rewriting history
- Recovering lost commits
The impact Git has had on our world is significant. This tool has enabled a level of collaboration that was not possible before and has changed how we work. There are several key reasons:
- Git is distributed. Any repository can pull and merge from any other repository. Thus, changes can flow in any route. This allows communities to self-organize as needed.
- Git is typically used in a pull (vs push) model where upstream maintainers pull changes from contributors, rather than a select group having write access to the repo who push changes. This allows anyone to easily make changes and propose they be included in the upstream versions, yet give maintainers control of what goes into the repo they maintain. The pull flow also encourages code review and collaboration as each pull request needs to be merged by a maintainer. This leads to higher quality work.
- Branches are very cheap, and merging works fairly well. Again, this is a big improvement on the previous generation of tools (example Subversion) where branching and merging was painful. This allows code changes to be easily integrated from multiple sources.
Metadata
Git adds the following metadata to your source code, design files, and documentation:
- commit messages
- history of every change
- tags for various releases
- pull requests (to group commits)
- conversations in pull requests
This metadata is simple, but allows for powerful workflow processes.
Parts of a Git System
The block diagram below shows the various parts of a Git system.
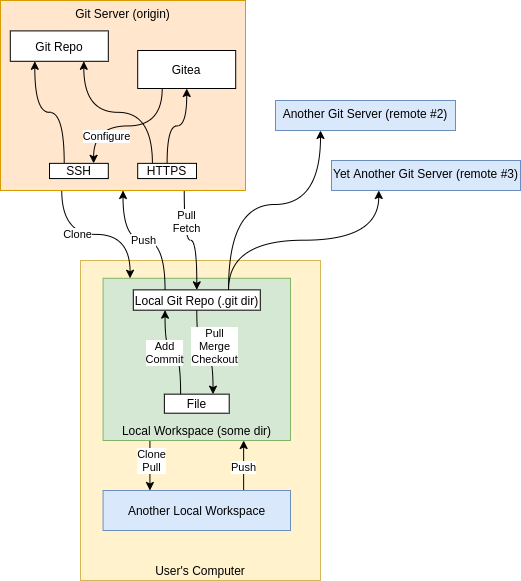
Typically there is a Git server and developers local workspace. But, there can also be additional remotes (shown in blue). While this may seem a bit complicated, it is very powerful and allows you to do flows like:
- clone an open source project
- modify the source code
- push the source code to your own Git server (a second remote) and collaborate with several developers.
- continue to fetch changes from the original (OSS) repository and merge with your changes.
- once finished, send a pull request to the upstream OSS maintainer to pull your changes from your git server.
The Pull Request Flow
Git pull requests are central to effective collaboration (as mentioned before). The basic flow of a pull request is shown below.
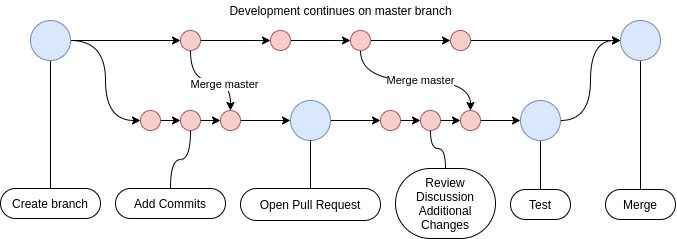
Several points to note:
- The branching, development, and commits typically happen in your local Git workspace.
- The pull request is created it Github/Gitea/Gitlab, and discussion happens in that interface.
- If active development is happening on the master, it is recommended to
git fetchandgit merge origin/masteroccasionally to prevent merge headaches at the end.
Most Git hosting applications/providers offer an option to protect the
master/main branch from direct commits. This encourages developers to work on
branches and use pull requests to merge their work.
Workspace and remote repos
Git is a powerful tool, and like most powerful tools it is easy to shoot
yourself in the foot and get things in a mess if you don't understand how it
works. The most fundamental concept to understand is Git has a full repository
in your cloned workspace. You can also have one or more remote repositories
specified. The state of your local repository may or may not match the remote
repository.
The following commands change the state of your local repo:
commitmergeadd
The following commands interact with remotes:
pushpullfetch
Remotes may be changed by other people while you are working, so this is why the
state of the remote may not match your local repo. A pull or merge can be
used to combine the changes in a remote repo with your local repo. After a local
repo is fully merged with a remote, you can then push your local repo branch to
the remote.
Branches
Another key concept of Git is branches. This is one thing Git does extremely
well and really differentiates it from previous version control systems like
Subversion. When you create a branch (git checkout -b <new branch> or
git switch -C <new branch>), it exists in your local repo, but not in the
remote. To push your branch from the local repo to the remote, you need to do
something like:
git push -u origin HEAD
The -u option tells git to connect your local branch with the remote so that
on future pull/push operations, git knows which remote to synchronize the
local branch to. Multiple remotes can exist, so Git needs to know which origin
should be used.
Working with branches
If you are working on a branch, please merge origin/master before doing work.
Otherwise, you may end up with a messy PR where tons of files are in the PR that
did not really change. This makes things difficult to review.
Also, you should only commit the files you are working on changing. Again, if you commit everything that happens to be touched, this makes the PR hard to review. One flow is:
git pullgit merge origin/master- do your work
git add <only files you intended to change>git commitgit push
Now you may be left with some files that got changed by the process of doing work, but you don't want to commit. At this point (once everything is safely committed), do a:
git reset --hard
This resets your workspace.
If you branch has not been worked on in awhile, it is cleanest to just reset it to the current master before doing work. Again, the goal is to minimize unnecessary merges:
git checkout <your branch>git reset --hard origin/master(this unconditionally forces your branch to match the master branch)git push -f(force push your branch)
Force push should be disabled on the master branch in your remote repos.
Again, the goal is to have commits/PRs that are easy to review.
If you only want to add a few of your commits to a PR, you can create a new branch, and then cherry-pick the few commits you want in the PR:
git checkout -b <new branch> origin/mastergit cherry-pick <hash>git cherry-pick <another hash>git push -u origin HEAD- (click link to create new PR)
- etc
Getting change notifications
With Github, Gitlab, and Gitea, you can configure whether you receive email notifications on repository activity. This is done by clicking the watch or bell button on the repository home page. Different hosting services/applications offer different levels of watching, but if select the highest level, you will receive emails on commits to pull requests. You can protect the master/main branch so changes cannot be pushed to it. This forces all developers to work on branches and merge changes using pull requests (use the PR flow described above in the Working with branches section). It is important to create the PR before committing and changes to the branch. Then anyone watching the repo will receive email notifications for every commit.
Rewriting history
Git is such a powerful tool that it even allows you to rewrite history -- well, at least in your Git repository. This is very handy as you can do work in your local repo, remove commits, merge commits, etc. This process can be used to clean up your commits before you push them to a remote. The following command can be used to:
git rebase -i HEAD~10
What this command does is an interactive rebase of the last 10 commits. You can delete, merge, re-order, and edit various commits.
You can also throw away the last X commits.
git log- note hash you want to return to
git reset --hard <hash to return to>
This throws away any commits after <hash>. Be very careful with this as you
can throw away useful work.
After your local commit history looks clean, you can then push it to the remote repo for review and merging.
Recovering lost commits
Occasionally you may lose a commit. This may happen if you commit a change
when you are not on any branch (common when using submodules). Git never throws
anything away, so fortunately you can usually recover the commit by typing
git reflog and then cherry-picking the lost commits after you switch to a
branch.
Community
TODO
Documentation
Contents
- The Role of Documentation
- Lead With Documentation
- Share Information in Documentation, not Email or Messaging platforms
- Why Wikis don't work for development documention
- Tips for successful documentation
Sub topics:
The Role of Documentation
Documentation plays an important role in development. There are several ways we can approach documentation:
- As a set-in-stone specification that is used to drive the implementation of the project. In this model, senior developers or architects write the specification, and any changes to the specification need to be made by the original authors of the document. By the end of the project, the documentation is usually out of date and may bear little resemblance to what is actually produced.
- As an active, living document that changes as the design changes and is used as part of the design process. As requirements and conditions change, the document is used as part of the thinking and collaborative process. When new features are starting, the approach is thought through and briefly documented before implementing. As the development proceeds, additional notes and changes are made to the documentation to reflect the approach, why things were done a certain way, etc.
- Something that is done after the fact. This documentation is often of poor quality because the developers are not interested in this task -- they want to move on to the next project, and technical writers often do not completely understand the technical aspects to accurately capture the knowlege that should be captured.
Realistically, most probably spends time in all of the above, and there is some value in each, but the more time you can spend doing active, living documentation, the better your documentation will be, and the better your thinking will be.
Lead With Documentation
What this means in practice is when we start working on anything that requires a little up front thought, architecture, or planning, the first thing we do is open up the documentation for the project and start writing. If collaboration/discussion is required, we open a pull request to facilitate discussion. However, the approach is still documented in the repo files, not in the PR, Github issue, etc.
This is very different than how most people work, but it is enjoyable and productive. It takes effort to switch as our tendency is to put too much documentation in Github issues, emails, etc. Old habits die hard and change takes time.
For this approach to be effective, documentation needs to be frictionless. Markdown is one solution – preferably in the same repo as the design/source files. Then it is easy to edit code and docs in the same editor.
Some of the benefits to this approach:
- when you are done with a task, the documentation is already done. Doing documentation after the fact is a rather distasteful task. However, if documentation is done before the task, it is very engaging.
- it helps you think. As Leslie Lamport says, To think, you have to write. If you’re thinking without writing, you only think you’re thinking.
- documentation does not become stale, outdated, and useless.
Share Information in Documentation, not Email or Messaging platforms
When someone asks for some information or how to do something, it's easiest to just replay to an email, send a message in slack, etc. However, a better approach is often to write some documentation, then share a link to the document. Then the information is easily re-usable the next time someone asks, or even better, people can find it themselves. This is a personal habit that will multiply and scale your efforts. There are several other benefits:
- you will put a little more effort into a document than an email reply, so the information will be higher quality.
- the information can be improved over time.
Many people enjoy the feeling of power that comes from others needing the information they have in their head or private archive. It feels good to be needed and pushes people toward being the gatekeepers of their domain. However, a more important question is are we effective? Are we optimizing for the short term (feels good) or the long term (sustainable results that scale)? Do we want our work and what we discover along the way to trancend ourself, or is our only goal to serve ourselves?
Why Wikis don't work for development documention
In a successful wiki, like Wikipedia, the documentation is the end goal, so it is the focus – so a wiki works well there. In development documentation, the documentation is NOT the end goal, so it is not the focus so documentation in a wiki tends to be easily abandoned.
This commentary on the OpenBSD documentation is interesting. A quote:
No wiki §
This is an important point in my opinion, all the OpenBSD documentation is stored in the sources trees, they must be committed by someone with a commit access. Wiki often have orphan pages, outdated information, duplicates pages with contrary content. While they can be rich and useful, their content often tend to rot if the community doesn't spend a huge time to maintain them.
Wikis are extremely easy to edit (very low friction), but this results in no workflow. Workflow or process is essential for quality and collaboration. Markdown in Git is almost as easy as a Wiki to maintain, plus it has the added benefit of PR workflow. In some cases Markdown is actually easier for developers as you can make documentation changes directly in your code editor while editting code.
Tips for successful documentation
- docs must live in repos as close to design/code files as possible so they can be maintained as part of your normal development process.
- documentation must be in a format that is easy to review, edit, and maintain (Markdown seems to be the pragmatic choice)
- documentation must be open, accessible, and easily found. Again, Markdown shines here because you can easily link from one document to the next. You are not limited by the strict hierarchy of a filesystem. It is also easily viewed in the Git management tool (Gitea, Github, Gitlab, etc) without opening the file in another application.
- you must develop a culture and workflow where:
- knowledge, decisions, theory of operation, etc is captured in documentation, not lost in the black hole of email and meeting discussion.
- documentation is integral with the development process
- discussions center around documentation
This all is hard -- really, really hard. But, I'm convinced it is one of the great differentiators.
Some things you should consider not doing when working in a development team:
- email a document. Instead check it into a repo and email a link.
- write long technical information in an email. This information will be lost, instead write it in a document, and then send a link.
- extensively discuss things in email if there are better mediums like PRs, issues, forums, etc. where the discussion is accessible to anyone who has access and throughout time.
Documentation Formats
Contents
- Requirements
- Options
- Example Scenario
- The difference between the push and pull model
- The Choice
- But Markdown/Git is too hard
There are many ways to create documentation. Microsoft Word is the standard in the business world. Developers often use Markdown in README files. Online systems like Google docs can be handy for collaboration on a document. Content management systems like Wordpress fit well for blogs and web sites. Sometimes a raw text file makes sense.
This document explores the use of a documentation system in an organization when more than one person needs to maintain or review a document.
Requirements
What are the requirements?
- Relatively easy to use
- Encourage collaboration
- Easy to track changes and review
- Support any organization structure
- Rich formatting
Options
We are going to examine three options in this document:
- Microsoft Word
- Google docs
- Markdown stored in Git
Microsoft Word
Most people probably reach for MS Word these days, as we've been conditioned to do so. It is the "expected" document format in the business world. It is a powerful tool and delivers impressive results with very little work. However, there are some drawbacks to using Word:
- Most software developers these days don't run Windows. This may come as a surprise to many but if you observe what people are using at tech conferences during presentations, and wander through the offices of leading tech companies, you will see mostly MACs and a lesser number of Linux notebooks/workstations. This is not an arbitrary choice or fad -- there are very good reasons for this which are beyond the scope of this document.
- Even though Word can track changes, it is tedious to review them. It requires downloading the file, opening the file in Word, and looking through them. History can be reviewed, but it is usually too much effort to bother.
- When someone commits a Word document to a Git repo, the changes are not easily visible in the commit. Again, if you want to see what changed, you need to check out and open the file. And, the history in Word is not necessarily tied to the Git commit history.
- Multiple people can't work on the same document at the same time.
Google Docs
Google docs is a very impressive tool and excels in scenarios where a small number of trusted people want to collaborate on a document. The ability for multiple people to type into the same document and see each other's edits in real time is very neat (very handy for composing notes during a meeting). Edits are tracked, and it has all the normal features such as comments that can be useful. However, there are also drawbacks to Google docs in that a connection to the cloud is required to use it and changes can't be managed outside the normal sequence of revisions.
Markdown
Markdown is a fairly simple markup language where you can create nicely formatted documents with a simple and readable text document. As with everything, there are trade-offs. The simple/readable text format also means there are limitations to what all can be done with it. However, the functionality included in markdown is adequate for most documentation tasks.
Some of Markdown's drawbacks:
- Is not WYSIWYG, although tools like Typora reduce this concern.
- Is a markup language so you need to know the syntax.
- Requires a little work in setting up a good editor, automatic formatters, etc.
- Can't do all the advanced formatting that other solutions can.
- Image files cannot be embedded in the document source file -- they must live in files next to markdown source.
However, there are also some significant advantages to Markdown stored in Git:
- Because the source file syntax is simple, it is very easy to review changes in a commit diff.
- The document/markup is very readable in a text editor -- developers don't have to leave their primary editor to work on documentation.
- Syntax is easy to learn and use, but there are tools like Typora that give you a more classic word processor experience.
- Encourages collaboration.
Example Scenario
Consider this scenario where we examine how things might go if the company handbook is maintained in Word, Google docs, and Markdown.
If the document was entirely in Word, the flow for an Employee to suggest a change might go as follows:
- employee emails the suggested change to someone in HR in the form of: "consider changed sentence "abc" on page 23 to "xyz"
- the maintainer of the handbook would have to make sure she had the latest version of the document -- perhaps she asks another person in the department for the latest version of the file, and that person emails the file to her
- she opens the Word document and makes the change with change tracking enabled
- a copy of the document is emailed to the CEO for review
- the CEO would email back some suggestions
- the maintainer would have to coordinate with the original author
- at this point, since everyone is busy, this task gets lost in the black hole of our overflowing in-boxes and is never completed.
Consider the alternative flow if the document is stored in Google Docs:
- employee has a suggestion, but cannot be give access to change the document in Google docs directly, as it there is no formal review process
- so, he emails the suggested change, similar to the Word scenario
- maintainer makes the change and notifies CEO to review
- review process is much easier that Word as both CEO and maintainer have write access to the document
Consider the alternative flow in Markdown stored in Git:
- employee checks out out handbook source
- he makes the change in a text editor (or tool like Typora) and pushes to a forked repo in his own namespace
- in the git portal (Github, Gitlab, Gitea, etc), a pull request is opened
- the maintainer of the handbook reviews the pull request and tags the CEO in the pull request to see what he things
- the CEO gets an email and reviews the pull request making a few suggestions
- the original author makes the changes and submits an updated pull request
- the handbook maintainer approves the pull request and the change is instantly merged into the master branch
- the CI (continuous integration) system sees a change in the master branch and generates an updated copy of the handbook and deploys it the company webserver (could be internal, or in the case of Gitlab, external)
Even though Markdown and Git may be less convenient to use than Word or Google docs for actually making an edit, collaborating on the change is much easier. Even if the maintainer takes a two week vacation in the middle of the process, when she gets back, the pull request is still open, reminding everyone of the pending change that needs completed. There is now process and tools that facilitate review and collaboration. Even though the editing process is a little harder, there is much less friction in the overall process of contributing a change to a shared document. Thus, more people will contribute as there is a low friction process to do so.
The difference between the push and pull model
The Markdown/Git flow described above is a "pull" model in which a person makes a change, publishes the change, and then the maintainer of the upstream document or project can easily pull the change in with a click of a button. This is different than the "push" model where a person might try to push a change into a document by emailing a suggested change, or might make the change directly in a Google doc. The big advantage of the pull model is that it enables process, tools, and workflow. A few more notes on the pull model:
- The change is considered in the context of just that change and not mixed in with other changes. It can be easily reviewed in the pull request. Tools like Gitea, Github, etc allow discussions to happen in the pull request. Pull requests can be updated after comments are processed. Once everyone agrees on the change, it is easy to merge with a single button click.
- There is a clear record of all changes and history that is easily reviewed. Additionally, with git blame, you can easily examine the history of any line in a file.
- Multiple changes can be happening in parallel and each proceeds at their own
pace. In Google docs, a change is made and then recorded. You can revert to a
version of a document, but it is not easy to isolate a change by itself and
merge it in when desired. If you want to revert a single change, you can't go
back in history and pull out a single change -- this is easy to do in Git with
the
revertcommand. - The pull model allows any organizational structure. The maintainer is free to merge or reject any proposed change. Direct access to the master copy is never required by contributors. In Git systems like Github, Gitlab, and Gitea, permissions can be assigned to repositories, but also branches within a repository.
- Multiple levels can also be organized. For instance, an engineering manager could be given responsibility for the engineering section in the handbook. He might collect contributions from members of that department, and submit one pull request to the company maintainer of the handbook. The changes can be staged in separate repositories, or branches within a repository.
The pull model is one reason Open Source projects have been so successful. The organizational structure of the Linux kernel is rather complex (with many levels). There are many subsystem maintainers who collect changes from contributors and then pass through multiple levels upstream. This process is all enabled by the Git distributed version-control system.
The difference between the push and pull models is the pull model scales.
The Choice
The choice of a documentation tool selection comes down to the following questions:
- Do we want to optimize for ease of editing (the short term)?
- Or do we want to optimize for collaboration and the spread of ideas and information (the long term)?
A casual study of various successful companies and open source projects suggest that reducing the friction of collaboration is critical to success -- especially in technology companies developing cutting edge/complex systems. Gitlab's handbook is maintained in a Git repo and anyone can open a pull request. While most of the contributions come within the company, there have been outside contributions. For more information on Gitlab's approach consider the following:
- The importance of a handbook-first approach to documentation
- Creating GitLab's remote playbook
- Leading GitLab to $100M ARR
But Markdown/Git is too hard
Can non programmers learn Markdown and Git? This is a good question and not sure I have the answer yet, but I think they can. In many ways, learning a dozen elements of the Markdown syntax is simpler than navigating the complex menu trees of Word trying to figure things out. Git does have a learning curve, but the essence of it is fairly simple. Once you understand the basic concepts and operations, it is as natural as anything else.
See the following vidoes for demonstrations on how to edit Markdown files in Gitea. The process in Gitlab and Github is similar.
Humans are inherently lazy, so most continue to just do what they have always done. Additionally, not all people are intrinsically motivated to share and collaborate. Probably the most important thing is to establish an organizational culture where the people at the top set the example, and ask others to follow. As much as we don't like to compare ourselves to sheep, most of us resemble them more than we like to admit -- we don't like to be driven, but will gladly follow the lead if it makes sense to us. Telling people to collaborate and use certain tools will not work if the people at the top of an organization are not doing the same.
Markdown
There are many trade-offs with documentation formats. Many of these have been discussed already. There are richer markup formats that are highly recommended such as Asciidoc and reStructuredText. If you are writing a book or public facing product documentation that needs extensive formatting, then the more powerful markup languages are a good fit. However, for development documentation where we're simply trying to capture some knowledge, formatting is rarely large concern. The basics features of Markdown are usually adequate and do not impose much burden on developers to learn. Markdown is not the most powerful tool, but it is the pragmatic tool.
Additionally, many collaboration tools now use Markdown for comments, descriptions. This is a much better experience than the WYSIWYG editors of yore. Examples of tools that have embraced Markdown include Trello, Github, Gitlab, Gitea, and Discourse. These tools are a joy to use. And one of the reasons is the editing experience -- it is so simple and smooth, but yet Markdown gives you the power of rich formatting when you need it.
The common use of Markdown gives you an easy way to migrate content from chat messages to issues/forum comments to documentation.
The CommonMark standard
The CommonMark specification that most tools now use as a baseline for their Markdown implementations. It is called CommonMark because the original Markdown creator did not allow the use of the term Markdown.
Formatting
Like code formatting, there is value in a team using the same format for Markdown. Prettier does a good job at auto-formatting Markdown. Many editors can be configured to format Markdown on save by adding the following file to your project:
.prettierrc
printWidth: 80
proseWrap: always
Platform
Contents
- Selecting the right technology
- Control
- Building
- Do you own your platform?
- Your personal platform
- Open Source
- Examples
- TODO
(also see our podcast on this topic)
With complex systems, it is important to consider your technology platform which is the base technology on which you your product is built. Some examples might include:
- an operating system
- programming language
- tools
- System on Chip (SOC) and other complex integrated circuits
- application libraries/packages
- cloud providers (AWS, GCP, Azure, etc)
- knowledge re-use
- technology that we build and reuse over time
Modern products must be built on existing technology -- you don't have enough time to re-invent everything from scratch. This reuse, which is greatest leverage we can bring to modern products, is also our biggest risk, for it is often problems in the base technology on which we build that is our undoing, because these problems are out of our control. This has never been more evident than in the chip shortages following the COVID-19 pandemic. Many companies are having trouble shipping product due to some component shortage.
Everyone has their priorities, but common desirable qualities of our platform might include:
- available - can we get the technology when we need it?
- stable - does it perform as we expect it to? can we get support or fix it when it breaks?
- predictable - does it always produce the same result?
- adaptable - can it be used in a wide range of products and problems?
- composable - can it be easily combined with other technologies?
- reusable - can we reuse our platform in multiple products?
- extensible - can new features be added easily?
- openness - is it easy to onboard new developers or is the platform locked up in the mind of of a few people? Is it well documented?
- runway - is your platform actively being developed to provide new features and take advantage of new technologies?
- unique value - does our platform enable us to build products that are unique and provide good value?
- programmable - can functionality be controlled in a deterministic and controlled manner (IE programs) and is it conducive to automation?
There are three perspectives to consider, which will be examined in turn.
- selecting the right technology for your platform
- having an appropriate amount of control over your platform
- building and investing in your own platform
Selecting the right technology
If we don't select the right technology to build on, not much else matters. Using new technology brings significant advantages to a development, and also risks. Companies who are in the mode doing things the way they always did them whither and die. Companies that are reckless in adopting new technology often crash and burn as they can never get things to work. The art is in knowing what is available and when to adopt it.
A developer in this age must continually watch what is going on around him and stay current with new developments. Time must be allocated for reading, investigation, and experimentation. The superpower in this age is not necessarily knowing everything, but knowing who to ask. Are you connected with the people who are experts and can provide you with the information you need when it comes time to select technology?
Control
With your platform, control is also a balance. You can't realistically know and do everything in your platform, but must have the ability to fix problems and adapt the platform as needed. Are you connected with the right people and communities who understand the technology you are using? Again, the superpower is not in knowing everything, but knowing who to ask, and being humble enough to admit when need help. Do you participate and add value in the open source communities that produce the technologies you use, or do you just expect them to fix your problems for free?
Building
A successful platform must be to some extent unique. For small companies/teams, it may be mostly a combination of other technologies/platforms and the value is in how they are combined. But, there must be something unique about your platform. If you build a product on an single existing platform without doing anything hard, there is likely not much value in the product you are building. For there to be value, you need to do hard stuff. And if you do hard stuff, it is nice if you can easily re-use that effort in the future.
Successful technology platforms have values. These values attract developers with similar values.
Do you own your platform?
On the surface, this question may seem ridiculous, for no one company can own all the technology that goes into modern products. However, to the extent you own your platform will determine your destiny and success. Apple is an extreme example of this -- they own their platform. Few of us will build things on that scale, and many of us have no desire to work at that scale. But, there plenty of hard problems left in this world that will only be solved by the magical combination of reuse and innovation, and then being able to leverage this development (your platform) is what produces high value.
Your personal platform
Thus far, we've been discussing the concept of a platform in the context of a company developing products, but we can apply these concepts personally as well. What do you know? Who do you know? What experiences do you have? Have you learned from them? What skills can you develop in the future? How can these be combined to provide something unique and valuable? Are you doing hard stuff -- reusing what you have learned, or are you coasting? Are you generous with what you know?
Open Source
Many of the most useful and technologies available to developers today are now open source. Some examples include:
- Linux
- Wordpress
- OpenEmbedded/Yocto
- languages like Go/Rust/Elm
Examples
Linux vs Windows CE
TODO
Embedded Linux vs MCU/RTOS platforms
There have been so many MCU operating systems/platforms that have come and go over the years. Years ago I recall being frustrated by the difficulty of embedded Linux and was attracted to the Dallas Semi-conductor TINI platform. This was a custom 8051 microcontroller designed to run Java code. TODO ...
Yocto vs OpenWrt
Cloud services vs your own server
TODO
- media (own blog website vs Linkedin, twitter, etc)
- brand -- you are your own platform
Hardware
This document describes best practices and reference information useful when designing hardware (printed circuit boards, etc).
Tools
There is no one tool that is perfect for all jobs -- that idea is delusional. The critical thing is to use the best tool for the job at hand. Some questions to consider:
- cost of the tool. Is the price a purchase or subscription model.
- how often will I be using the tool. Am I an occasional user, or is this my full-time job?
- barrier to others contributing. Collaboration is key, so tool choice should be made with the thought of enabling collaboration.
- how long do I need to maintain the design? You will need access to tools for the life-cycle of the design.
- support -- is there a company or community who can support me when I have questions or problems?
- how am I going to maintain part numbers, BOMs and other manufacturing data?
- if outsourcing the design, will I have the ability to maintain it, or easily get someone else to work on it?
For basic designs KiCad works well. As of version 5.1, it has all the essential features needed for efficiently capturing schematics and laying out PCBs. However, if you have a large design with a lot of high speed signals, then you may need something better.
This brings up the question -- why should I use KiCad when I have an Altium (or some other high end tool) license? Lets phrase this another way -- even if you owned an excavator, would you haul it in to dig a hole to plant a small tree in your yard instead of owning a shovel? No, everyone with any property owns a shovel, or likely several. It is quicker to get out for small tasks. Other people (like your kids) can use it. Likewise, KiCad can be used on any computer anywhere by anyone who spends a little time to learn it, instead of just at your office on the machine that has the node-locked license. Someone else can make a small tweak to the design, or easily take over maintenance. In 6 years, you still have access to the tool if you need to make some changes because a part went obsolete. With KiCad in your organization, more people will become PCB designers. The manufacturing engineer may design a simple board to automate a production task. A project manager may fix a minor issue in a released design because no one else has time. For someone skilled in a high end tool, creating a design in KiCad may take a little more time, but over the life-cycle of the project, you will like save time.
Again, there are many factors and there is no one size fits all. Some designs are already done and need to be maintained. Some designers are unwilling to use something different than what they have used in the past. There are many factors, but at least consider the right questions.
See this article for more discussion on this topic.
Prototyping
The cost of building PCB boards in low quantity is continually coming down, so it is not much more practical to build prototypes often as advocated in this article. You learn a lot building something, so this should be done as early as practical in the development process. Some places to order prototypes:
Testing
TODO
Schematic Checklist
- decoupling caps located next to each other should be two decades apart, otherwise, they may form tank circuits and resonate.
- any power loss should drive interrupts to the CPU, so that we can recover if necessary
- review all external IRQs to make sure they are is no external IRQ muxing -- especially on Linux systems, this can be a pain to implement.
- create spreadsheet of IO and make sure all signals are available -- especially on SOM designs
- verify LCD data signal mapping is correct
- verify signal levels between various parts
- check pullups on all i2c signals -- ~5K
- battery powered systems should have a low voltage shutoff -- otherwise batteries will be damaged
- read battery voltage. Systems have a way of being used in applications that were not originally intended, and being able to read battery voltage is often helpful.
- if battery and AC powered, a GPIO should be available to tell if AC power is available. Even better, be able to read the input voltage. This allows early detection of some power problems.
- all power switches should be controlled slew rate. Use power switches instead of raw FETs.
- power sourcing -- especially in battery powered designs
- verify boot mode pins
- power sequencing
- place 0.1uF cap near the reset pin to help avoid ESD induced resets
- use supervisory chip with threshold above brownout and connect to GPIO to warn SW of potential power problems
- Verify trace widths of all high current traces
- USB: (todo, locate source) Other VBUS considerations are the Inrush current which must be limited. This is outlined in the USB specification paragraph 7.2.4.1 and is commonly overlooked. Inrush current is contributed to the amount of capacitance on your device between VBUS and ground. The spec therefore specifies that the maximum decoupling capacitance you can have on your device is 10uF. When you disconnect the device after current is flowing through the inductive USB cable, a large flyback voltage can occur on the open end of the cable. To prevent this, a 1uF minimum VBUS decoupling capacitance is specified.
Schematic Style
- Schematics are not only design entry — schematics are documentation. Unless you are writing all the software, handling all the manufacturing, and debugging all field issues yourself, there will be others who will be using them. Be considerate.
- Not everyone has a D size plotter (even B size printers are fairly rare). I have a rather large (27″, 2560×1140) monitor, and have seen schematics that I have to zoom in to read. Schematics should be created such that they can be printed on letter size paper (everyone has a letter size printer), and easily read — even by folks in their 60’s. This is fairly simple — just spend some time breaking large symbols into smaller sections, and use a few more pages. Even for viewing on a screen, putting less stuff on each page makes it easier to scroll through pages. Most people print out schematics for review or bench work — so having letter size pages makes this possible.
- Schematics should be organized to have one function per page, or group similar functions on a page. Don’t intermix power supplies and an audio codec unless they are related. We realize the importance of organizing software in modules, and a large schematic is really no different.
- Keep all pages the same size. When every page is a different size, you can’t easily scroll through pages, or print them out.
- Keep nesting levels of hierarchical schematics to a minimum. For most PCB designs, hierarchical schematics offer little advantage over a flat schematic logically organized on pages. PCB’s can only be so big, therefore even if you have 20 pages for a schematic, 20 pages is really not all that much, and adding hierarchy to 20 pages just adds complexity and makes them harder to read. In a sense, your schematic page becomes a “hierarchical block.” However in tools like KiCad, hiearchy is the only way to do multi-plage schematics and they can offer some benefit in showing how the different pages are connected together.
- Off page references are the key to making smaller schematic pages work.
- Spend a little more time putting a little art into your schematic symbols. If you have a DB-9 connector, and you draw a connector in the shape of a DB-9 (only takes a few more minutes), then you can instantly recognize what it is in the schematic, and it is much quicker to find the circuit you are looking for during debugging sessions. The same can be said for USB connectors, etc. In some cases, it may make sense to draw a connector symbol to match how it looks physically, so you can quickly find a pin on the bench without digging out a datasheet.
- Schematic text must be easily searchable. I don’t want to install a clunky schematic viewer that only runs on X.XX version of windows just to search for text. I want to use the PDF reader I already have installed. Make sure schematics are cleanly exported to PDF, and are easy to search.
Other references:
Software
Language Selection
As in many aspects of life, you can't have everything -- you need to optimize for something. One way to look at programming languages is what I'll call the "programming triangle." Similar to the project management triangle -- the programming triangle is: Fast, Reliable, Simple -- pick two -- you can't have all three.
- Efficient: speed and size
- Simple: language complexity, tooling, deployment, library/package availability, etc.
- Reliable: low run time exceptions, secure, easily decipherable stack traces, etc.
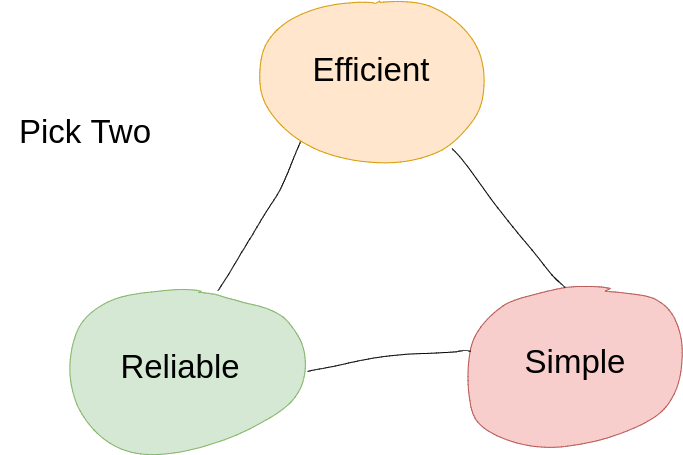
There is also the issue of optimizing for domains. Rust is fast when running on a native machine, but much slower and larger than Elm in the front-end. Thus it often makes sense to use different languages depending on the domain you are working in. Sometimes the domain dictates the language -- such as embedded microcontroller programming where often C/C++ is the only practical option. Some languages optimize one attribute aggressively at the expense of the other two. One example is Python -- it is very simple to use, but compared to other options is relatively unreliable and inefficient. However, when working on one-off data science problems, simplicity and ease of use is most important -- especially when paired with fast libraries. There is a huge difference between writing a program written by one person to solve one problem on one computer at one point in time (examples: data science calculations, excel macros, and university class assignments), and writing a program that will be developed by a team, deployed on many systems, and maintained over an extended period of time. In the first case (what I call one-off programs), it really does matter what you use. However, if we want a program to scale with developers, deployments, features, and time, then we need to think seriously about the programming triangle -- what is important for project success.
For programs that need to scale, we should be wary of languages that don't do any, or only one of these attributes well, such as Javascript on the backend. C++ is another example -- it is neither reliable or simple, but its momentum keeps it in high use, and sometimes the availability of libraries (such as Qt) make it a good choice.
When we think of a language, we might think first about the programming paradigm – procedural, object oriented, functional etc. There is much more to software development than the paradigm which is the “look” of the language. The programming paradigm can be important, but for programs that need to scale, what really matters is how the paradigm maps into the above attributes.
See also:
- Richard Feldmans presentation about Rust and Elm
Operations
Contents
(also see Security and Reliability)
We'll define operations as operating the digital infrastructure we depend on. For most companies operations is overhead and does not directly add to the bottom line. Thus, operations are means to an end, and not an end in themselves. Many IT personnel completely miss this point.
Freedom
Freedom, as defined by Richard Hipp (the author of SQLite), means taking care of yourself. In an operations sense, this means running stuff yourself where it makes sense. The alternative is to lock yourself into a highly proprietary solution from one provider that you can ever move away from. It is often more economical as well. A few examples:
- with one $5/mo server (Linode, Digital Ocean, etc.), you can host dozens of services and sites. Though more convenient, it is much more expensive to deploy these services individually on App Engine, Beanstalk, Heroku, etc.
- with one $5/mo Server, I can easily host email for dozens of people and domains using Simple NixOS Mail Server. The alternative is to pay per user at various mail hosting services.
There are tradeoffs -- if you have dynamic workloads that need to rapidly scale up/down or if you need the integrated groupware features with email, then the above may not make sense.
Selecting services
Don't use pay-as-you-go
Unless you really need to dynamically scale large, don't use pay-as-you-go (PAYG) services like AWS, Cloudflare, GCP, etc. unless you can set hard limits. Otherwise, a simple DNS attack can cause you to rack up $100,000's in bills. If you are running a small service, run your services on fixed-fee subscription service instead (ex: Linode). It may not be as cost effective, but the management overhead and risk is much less.
Can you get support if you need it?
99.9% of the time, everything goes fine and you don't need support. However, when you need it, it is critical you can get it -- like when you can't log into your account or a server upgrade failed. If you are not a big user, it may be difficult to get support from the larger providers -- taking days of endless hassle. Instead, select a smaller provider who offers good phone support (ex: Linode).
Diversify
You probably don't want to run all your infrastructure through one company. This may be the most cost effective, but has several risks:
- you'll likely get locked into proprietary solutions that are hard to move away from should your needs change
- if your account gets shut down or locked for some reason, you lose everything leading to days/weeks/months of lost productivity
Security
(also see Operations and Reliability)
With connected computers and devices, security is now an important consideration. There are several aspects to consider:
Threats
- privacy (I don't want others viewing my information)
- theft (I don't want others stealing my information)
- loss (I don't want others damaging or defacing my computers, equipment, information, web sites, etc)
Privacy
Privacy in the Internet age is largely an illusion, especially if you use mainstream cloud services. Even in you are on a perfectly secure computer system, you still might send a private email to someone, and they might forward it to people you did not intend to be recipients. The best policy with communication is to write with the assumption the message may be posted on a billboard some day. Never say anything about someone that you would not say to their face. This is basic integrity.
Theft
In the age of open source, your intellectual property is becoming less your code, schematics, and product ideas, and more your ability to execute and scale. The core technology we use (programming languages, browsers, operating systems, etc.) are all projects that exceed the scale of even the largest companies and governments. The hard part is integrating and managing this technology. Your "process" is the new IP.
For information to have value for thieves, there has to be someone who is interested in it. For most people and smaller companies, the only person interested in your information is you. This is why ransomeware is becoming more popular -- your information has very little value beyond yourself.
Another popular form of theft is when criminals compromise our computing resources and use them for their own purposes. They may use them to launch DoS attacks as a service, hide illegal activities, etc. This may even happen without our knowledge. As high-speed, symmetrical fiber Internet connections become more common, a simple Internet connected computer will become more and more valuable.
Loss
We are concerned that we don't lose the use of our digital information, infrastructure, or physical assets. Some examples:
- hackers maliciously destroy information
- hackers encrypt our data and demand ransom
- foreign agents compromise computers that control the power grid and shut off power or damage equipment
- we lose the password to our password database
- we lose the key to an encrypted hard drive and can't access our data
- security measures make our infrastructure hard to use, preventing work from getting done
- our password database is compromised, giving attackers access to every on-line account we operate.
- our computer is stolen, and ...
- the thief uses saved passwords in the browser to compromise online accounts.
- the thief uses ssh keys that are not password protected to log into servers we operate
- an attacker social engineers someone to give them the login information for various accounts
- our email server goes down, but a service required to run our email requires email 2FA to log in. Furthermore, this service only provides support through their web portal which we can't get to.
- someone launches a DNS attack on our service racking up huge hosting costs and shuts down a large number of online services we use
- the person who operates our infrastructure is out of commission and no one else has access
- a server crashes and we don't have backups or the backups don't work
The list goes on ... It because obvious there are many attack vectors that can cause loss.
Balance
With the topic of security, it is important to have some balance. If we are not careful, security measures can cause more damage than the threat we are trying to protect against. The benefit must always be weighed against the cost.
SSH
SSH keys should always be password protected so that if a machine is stolen or compromised, the keys can't be used to log into servers.
Password login should always be disabled on servers connected to the Internet and SSH keys used instead. This is fairly easy to do and drastically reduces the number of attacks. Even if you have very secure passwords, allowing password login will cause attackers to unceasingly try dictionary attacks on the system. More measure like fail2ban can be used, but it seems forcing key based login gets you 99% of the way there.
2FA, MFA Authentication
Two factor (2FA) or Multi-factor (MFA) authentication is becoming popular and now required for a number of services. Typically a email or SMS code is sent or an authenticator app on a phone is required. While this can help prevent an attacker from getting access to our account, it also increases the risk that we can't access our account ourself. Consider the following scenarios:
- we lose the use of our email
- our DNS domain is hijacked or expires
- we lose our login information
- payment method expires and the account is locked
- we lose the use of our phone
- phone number is hijacked
- phone is damaged, and we need our phone to log into the service that manages our phone service.
What is the impact of the above? How many days can we operate without these. Map it and make sure you have a recovery plan.
It may make sense to assign multiple people to critical accounts. There is more risk of the account being compromised, but less risk we'll be locked out of it.
Loosing access to our data through our own mistakes seems to be a much bigger problem in general than malicious actors.
Reliability
Contents
- Lower level mechanisms are generally more reliable
- Simplicity
- Essential and Accidental Complexity
- The network is a weak link
- Does using multiple services/computers increase reliability?
- Examples
Lower level mechanisms are generally more reliable
Lower level, widely used mechanisms are typically more reliable than higher level mechanism. For instance, a cloud object storage service will probably be more reliable than a hosted authorization service. Sending a TCP packet is typically more reliable than a specialized GRPC endpoint at a hosted service. Why? Becuse one is widely used and the other is not. The more we can standardize communication infrastructure, payloads, storage, etc, the easier it is to build reliable systems. For example, in the Simple IoT project, we standardize on points as the payload for communication and storage. If we can store, transfer, and syncronize points reliably, then the system generally works. We only have to make modifications at the edges. However, if we need to store, transfer, and synchronize dozens of different payloads and mechanisms, and modify every part of the system every time we add a feature, then it is more difficult to build a reliable system. This is why efforts like GraphQL and NATS are interesting -- they are standards for common problems and are widely used and therefore tend to be more reliable.
Simplicity
The only path to reliability is simplicity. We generally can't fix problems by adding more "stuff". As time moves on, technologies designed for one problem domain are no longer adequate. We may try to solve this problem by adding additional layers but this rarely works. Additional layers of abstraction are useful if they simplify our interactions with technology and the underlying technology is sound, however if their purpose is to gloss over problems where the underlying system is fragile and complicated, then the problem is usually made worse. Sometimes the best solution is to start over with something new which is better fitted to the problem domain.
Essential and Accidental Complexity
Modern systems are complex because of the type of problems we are trying to solve, which is called "essential" complexity -- we can't avoid it as it is part of the problem domain.
The type of complexity we must avoid is "essential" or "accidental" complexity.
The network is a weak link
A system is only as good as the weakest link and often the problems come from the areas we least expect. We can have replicated/redundant databases, load balancers with redundant web servers, etc. But one network problem can bring the whole thing down, which leads us to the fallacies of distributed computing.
- The network is reliable
- Latency is zero
- Bandwidth is infinite
- The network is secure
- Topology doesn't change
- There is one administrator
- Transport cost is zero
- The network is homogeneous
The Internet was designed to be redundant and reliable, and in many ways it accomplishes these goals very well. The problems most often come in at the edges of the network where there is no redundancy, or when we depend on a single company's WAN for security, etc.
Networks can also be compromised by denial of services attacks where latency can be driven up significantly. A service may fail if latencies cause communication timeouts to fail, or we can't get the throughput we need.
Does using multiple services/computers increase reliability?
If we are building a system, it may be temping to outsource everything we can (auth, storage, ingress, notifications, etc.) to 3rd party services with the assumption they not everything will go down at once if something breaks. There are good reasons to use services like Twilio which provide a gateway to external systems like SMS and the telephone network that are impossible for small organizations to do on their own. The reality is that if something goes down, there is a good chance your system will not be useable anyway, so much of the time, this "diversity" does not really buy us much, but rather introduces more risk and cost as there are now many more network connections between services.
The same question applies in the decision to use microservices or a monolith architecture. To misquote a wise man:
Some people, when faced with a coupling problem, think 'I know, I’ll use microservices!'. They now have two problems.
Others have written extensively on this subject:
- The Majestic Monolith
- Monolights Are The Future
- Integrated Systems for Integrated Programmers
- Gotime 135
- Staying Monolith or Microservices
- Monolith First
- The Neomonolith
Some problems are inherently distributed:
- IoT systems where devices are physically separated by some distance
- Browsers and webservers
- Applications that reach large scale
If you are not Google scale, then perhaps you should put everything you can on one server, run backups, and be done with it. Technologies like Litestream make this very practical.
Examples
Database connectivity issues
A system was built that using a database that was hosted by the company that produced the database. Multiple database nodes were used for redundancy to prevent data loss, down-time, etc. At one point, a service started loosing its connection to the database. The only way to recover was to restart the service. The db hosting company suspected network issues between the cloud providers that hosted the service and the database and could not provide any help beyond that. They suggested moving the service to the same cloud/region as the db. This was not practical to do quickly for multiple reasons so a watchdog was implemented that restarted the service when the db error count started to rise. After a week or so the situation resolved itself.
Network issues in a cloud provider
In another case, users could not log into a hosted IoT service. The root cause of the problem was a connectivity issue in the cloud hosting company their service used. They were able to resolve the issue by resetting the affected microservices. This same service was interrupted a few days later when the cloud company made changes to their WAN that impacted connectivity network connectivity between clients on the Internet and the cloud service.
In both of these cases, the network was the culprit and something beyond the control of any of the operations people involved. The only way to reduce these risks is to move services closer together -- same cloud region, same data-center, same subnet, same machine. While it may seem risky to put everything on one machine, at least you have control of that machine and can spin up another if needed.